生物无穷小——有机数据库
生物无限 - 有机数据库
化学博士。工程。西普里安-加布里埃尔·奇塞加-内格里尔
座右铭:
一开始很简单。解释宇宙的起源是相当困难的,无论它多么简单。我想每个人都接受这样的观点,即解释具有所有必要设备的复杂秩序——生命或能够创造生命的存在的突然出现是更加困难的。达尔文的自然选择进化论令人满意,因为它向我们展示了一种将简单转化为复杂的方法,一些无序的原子如何组合成越来越复杂的结构,直到最终创造出人类。
理查德·道金斯 (Richard Dawkins) – 《自私的基因》,第二章 – 复制者,第 14 页14,布加勒斯特,技术版,2001 年(译:Dan Crăciun)
一、摘要
反渗透: 本文主要描述了真核细胞的结构以及细胞质和细胞核的子结构,以帮助理解脱氧核糖核酸/DNA 如何作为包含细胞生长和繁殖所需的所有信息的数据库发挥作用。它还描述了 DNA 中包含的信息被转录为核糖核酸/RNA,然后用作核糖体内蛋白质合成模板的机制。文章的结构是描述真核细胞基本信息的元文本之一,真核细胞是高等生物体(包括人类)的组成部分。为了更好地理解所处理的主题,代表深入信息和参考文献链接的二维码已插入到文本中。
英语: 本文主要描述了真核细胞的结构以及细胞质和细胞核内的子结构,以帮助理解脱氧核糖核酸 (DNA) 如何作为包含细胞生长和繁殖所需所有信息的数据库发挥作用。它还解释了 DNA 中包含的信息被转录为核糖核酸 (RNA),然后用作核糖体内蛋白质合成模板的机制。这篇文章的结构是一种元文本,提供了有关真核细胞的基本信息——高等生物体(包括人类)的组成部分。为了更好地理解该主题,文本中包含了二维码,可提供深入的信息和参考书目。
关键词: 生物体、细胞、DNA、RNA、蛋白质、数据库
二.介绍
我们所生活的地球已有大约 45 亿年的历史。会很多吗?会不会有一点?事实上,它几乎是宇宙年龄的三分之一。大约 40 亿年前,第一种生命形式以单细胞原核生物的形式出现。这种细胞类型包括细菌和古细菌纲的成员。它们的特点是没有细胞核,但有鞭毛(大多数时候)、细胞膜、细胞质、核糖体和含有分散在细胞质中的遗传信息的核苷酸。
II.a.真核生物
真核生物是比原核生物复杂得多的生物。与原核细胞相比,真核细胞大约大一万倍。单细胞和多细胞真核生物都可以包括在这一类中。它们是属于动物(如人类)、植物(如玉米)和真菌(如香菇)的细胞。
该类的其他代表有:霉菌、原生动物和藻类。
II.b.真核细胞的组成部分
真核细胞描述于 图1。
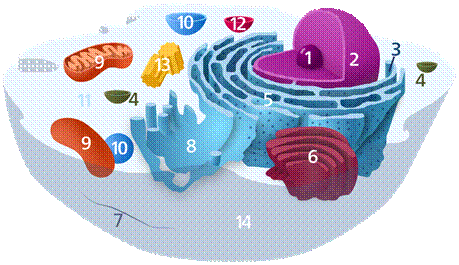
图1 – 真核细胞的结构:1 – 核仁,2 – 细胞核,3 – 核糖体,4 – 囊泡,5 和 8 – 内质网,6 – 高尔基体,7 – 细胞骨架,9 – 线粒体,10 – 液泡,11 – 细胞质,12 – 溶酶体,13 – 中心体,14 –细胞膜
它由以下组件组成(图1):
- 膜 (14) – 它覆盖细胞、控制物质进入或离开细胞并维持其电势;
- 细胞质——是一种凝胶状环境,占据了膜所包围的大部分空间。它包含以下 12 项描述的细胞质内亚结构:
- 核仁 (1) 是真核细胞细胞核中最大的结构。已知它是核糖体生物发生发生的场所;
- 细胞核 (2) – 包含几乎 99% 的细胞基因组/数据库。这是脱氧核糖核酸——核DNA(红细胞/红细胞中不存在)的所在地。它主要以染色体的形式组织/包装。细胞所需的所有信息都存储在这里。我们将进一步回到这个话题!
- 核糖体 (3) – 细胞质的子结构,其中以 DNA/RNA 信息作为模板进行蛋白质合成;
- 囊泡 (4) – 细胞内部或外部的结构,含有双层脂质包裹的液体或细胞质。它有助于物质从细胞中去除或进入细胞,以及物质跨膜运输;
- 内质网(5 和 8)——是真核细胞运输系统的一部分,具有蛋白质折叠/包装等功能;
- 高尔基体 (6) – 在蛋白质被送往目的地之前将其嵌入囊泡中发挥着非常重要的作用;
- 细胞骨架 (7) – 是一个由相互连接的蛋白质丝组成的复杂且动态的网络。在真核细胞内,它从细胞核延伸到细胞膜。赋予电池抗变形能力。它还参与许多其他细胞过程。
- 线粒体 (9) – 用于在 ATP(三磷酸腺苷)分子中以化学形式产生和储存能量;
- 液泡 (10) – 是细胞质中的封闭隔室,可以含有无机或有机物质(通常是酶溶液,在极少数情况下是固体物质);
- 细胞质 (11) – 也称为细胞质基质。它是溶解在大量水中的复杂物质混合物;
- 溶酶体 (12) – 它们是存在于许多动物细胞中的球形囊泡。它们含有水解酶,可以消化各种生物分子;
- 中心体 (13) – 是一种具有复杂功能的细胞器。
三.脱氧核糖酸 – DNA – 有机数据库
DNA是一种非常复杂的有机分子,但我会尽力尽可能简单地解释它!它是在 19 世纪初由瑞士生物化学家 Frederich Miesher 发现的(他,DNA ...☺),但直到 1953 年詹姆斯·沃森、弗朗西斯·克里克、莫里斯·威尔金斯和罗莎琳德·富兰克林才破译了它的结构,他们借助当时的新技术——X 射线衍射研究了这种分子。四位科学家证明DNA由两个相互“扭曲”的双螺旋组成,即所谓的α螺旋。
DNA所在的地方是细胞核(图1),它以代表染色体的几个 X 形结构的形式包装(并超级存档)。具体来说,人类有 46 条这样的染色体,分为 23 对。其中 22 对称为常染色体,在女性 (♀) 和男性 (♂) 中具有相似的结构,第 23 对有所不同,因为它编码有关生物体性别的信息。
我之前谈到的所有这些包装意味着,一个自由的分子,其长度接近2米的“巨大”(分子通常具有纳米甚至微米量级的尺寸)可以被存档在纳米量级的空间中(这大约是正常真核细胞的细胞核的大小)。包装是在称为组蛋白的小分子的帮助下完成的。为了解释清楚,我在中提供了详细的图形表示 图2。
据观察,在由糖分子(脱氧核糖,为了完整起见……与RNA中的核糖相似的糖……但失去了羟基-OH基团)和磷酸盐组成的骨架上, 图3-4 (源自 ATP——我们之前在简要介绍线粒体时所讨论的三磷酸腺苷:位置 (9) 图1)是核碱基,遗传字母表的 4 个字母:A – 腺嘌呤、C – 胞嘧啶、G – 鸟嘌呤和 T – 胸腺嘧啶(图4)。这些来自遗传字母表的字符一次组合两个,以连接 DNA 分子的两条链。腺嘌呤 (A) 与胸腺嘧啶 (T),通过 2 个氢键,A === T 和胞嘧啶 (C) 与鸟嘌呤,通过 3 个氢键,C ==== G (图3-4)。
序列中的几个核碱基组成了一个基因,而基因包含了细胞生长和繁殖所需的所有信息。细胞繁殖时的 DNA 复制不是本文的主题......
其中许多基因编码蛋白质(一串串的氨基酸长序列),这些蛋白质可以是:酶、运输物质、激素甚至神经递质(例如在两个神经元之间的突触空间中)。 DNA 还编码精子受精的卵子生长和发育所需的信息,直到获得功能齐全的有机体的那一刻 ......但关于这一点在下一章......
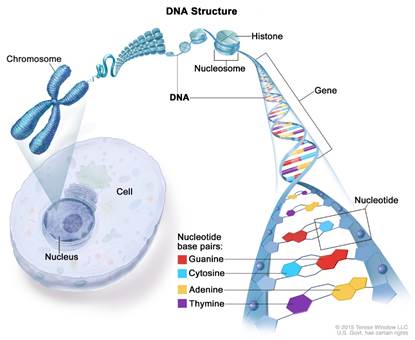
图2 – DNA 在细胞核中的位置及其包装
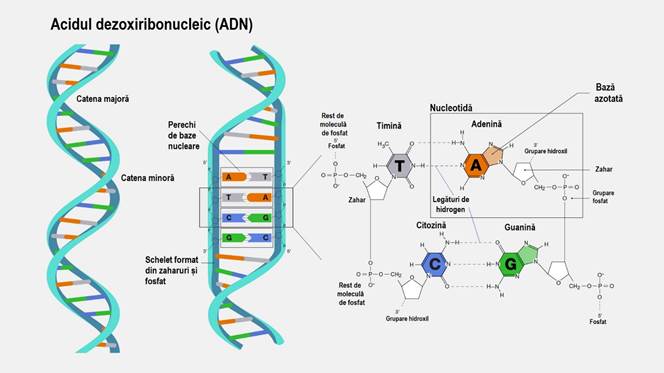
图3 – 包括两个卷曲螺旋(α-螺旋)和核碱基的细节:腺嘌呤 (A)、通过 2 个氢键结合的胸腺嘧啶 (T) A === T、胞嘧啶 (C)、通过 3 个氢键结合的鸟嘌呤 (G) C == G
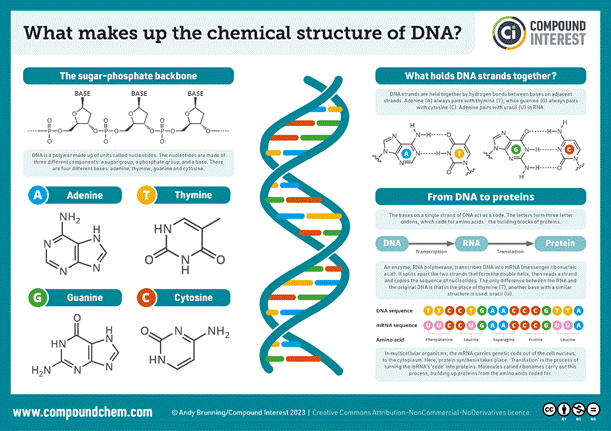
图4 – 核基地的结构和两条主链的骨架
四. RNA – 核糖核酸胞内转运蛋白
RNA 是一种比 DNA 稍微简单的分子。如果DNA有两条相互缠绕的链,那么RNA只有一条链。 RNA 链主链中的糖称为核糖,如上一小节所述。 RNA字母表仍然有4个字符,但有一个碱基与DNA中的不同。因此,有:腺嘌呤(A)、胞嘧啶(C)、鸟嘌呤(G)和尿嘧啶(U)。请注意,胸腺嘧啶不再出现在该字母表中。因此,当 DNA 转录为 RNA 时,胸腺嘧啶被尿嘧啶取代:腺嘌呤转录为尿嘧啶,胞嘧啶转录为鸟嘌呤,鸟嘌呤转录为胞嘧啶,胸腺嘧啶转录为腺嘌呤。
RNA的主要作用是将信息从细胞核中的DNA携带到细胞质中的核糖体,在那里它被用来合成细胞在任何给定时间所需的蛋白质。
RNA 有多种类型:
- 信使RNA——将编码信息从DNA携带到核糖体;
- 转移RNA——涉及氨基酸以有序方式连接成蛋白质(核糖体内)的机制……但我不会在这里详细介绍;
- ARN 核糖体等
对于DNA上编码基因信息的转座机制(在真核生物中——包括人类——几乎97%的DNA信息在蛋白质合成中没有作用)我将继续只讨论信使RNA——mRNA。
V. 将信息从 DNA 转录为蛋白质(氨基酸序列)
正如我们之前所说,信使 RNA(mRNA)是细胞内信息的载体。当需要转录基因信息时,一种称为 RNA 聚合酶的酶就会附着在 DNA 结构上。这会解开两条链,并使核碱基相距 10 – 20 个字符(A、T、G、C)。进行转录的链称为模板(反义)链,另一个非模板(编码)链。 DNA 上的碱基如以前一样转录:腺嘌呤 (A) 为尿嘧啶 (U),胞嘧啶 (C) 为鸟嘌呤 (G),鸟嘌呤 (G) 为胞嘧啶 (C),胸腺嘧啶 (T) 为腺嘌呤 (A)。
例如(这里我们采用了 27 个字符,但转录的基因通常更长):
如果在编码链上我们有:
| 一个 | 时间 | G | C | G | G | C | 一个 | C | G | 一个 | 时间 | 时间 | 时间 | C | C | 时间 | G | 一个 | 一个 | C | C | C | G | 时间 | G | 一个 |
在对应模板链上产生:
| 时间 | 一个 | C | G | C | C | G | 时间 | G | C | 时间 | 一个 | 一个 | 一个 | G | G | 一个 | C | 时间 | 时间 | G | G | G | C | 一个 | C | 时间 |
RNA链被转录:
| 一个 | U | G | C | G | G | C | 一个 | C | G | 一个 | U | U | U | C | C | U | G | 一个 | 一个 | C | C | C | G | U | G | 一个 |
它被称为 mRNA 或信使 RNA。
此时,我们继续进行 mRNA 处理,因为并非所有信息都是编码的。 mRNA 的某些部分将被排除,这些部分称为内含子,剩下的序列称为外显子。这些外显子聚集在一起形成信息,这些信息将到达核糖体进行蛋白质合成。这里读取序列上的“字母” 一次 3 个并表示为单个氨基酸。这些字符有64种组合,而氨基酸只有20个,这意味着一个氨基酸可以由多组3个字符编码。有一个 START 组合:AUG 和 3 个 STOP 组合:UAA、UAG 和 UGA。但是氨基酸将在拉丁字母表中的下一个字符序列中讨论!
V.a.氨基
人类遗传学中有 20 种氨基酸,每种氨基酸都有自己的化学式,如 图5 并在 表1 从续集。所有这些氨基酸的共同点:碱性氨基 -NH2 和羧酸基团 -COOH (其中R代表此处未指定的某个基团)。
由于氨基酸分子的这种特殊性,几个这样的分子可以相互结合形成以下类型的长链:
H2N – C(R1) – (C=O) – HN – C(R2) – (C=O) – HN – C(R3) …….. (C=O) – HN – C(Rn)——噗……而且......看,这就是我如何“迷惑”你的,直到我描述了蛋白质是如何形成的☺! 在生物或生化系统中,事情比这更复杂一些,但我将在下面的段落中更详细地解释。
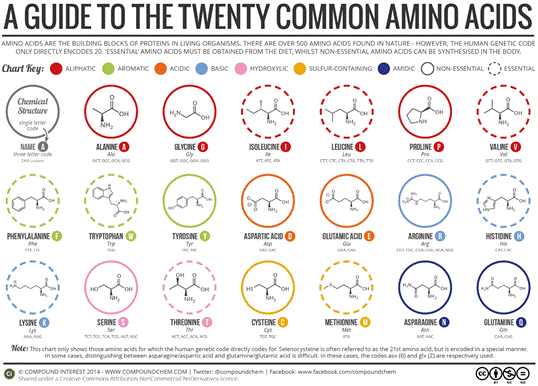
图5 – 最常见的氨基酸
表1 – 氨基酸名称、符号和分子的电荷
| 姓名 | 3个字母的符号 | 符号 1 个字母 | 极性 | mRNA 上的编码组合 |
| 丙氨酸 | 翼 | 一个 | 中性的 | GCU、GCC、GCA、GCG |
| 精氨酸 | 精氨酸 | 右 | (+) | CGU、CGC、CGA、CGG、AGA、AGG |
| 天冬酰胺 | 阿森 | 氮 | 中性的 | AAU、AAC |
| 酸性天冬氨酸 | 天冬氨酸 | D | (-) | 闭嘴,嘎克 |
| 半胱氨酸 | 半胱氨酸 | C | 中性的 | 教资会、教资会 |
| 酸性谷氨酸 | 谷氨酸 | 乙 | (-) | GAA、GAG |
| 谷氨酰胺 | 谷氨酰胺 | 问 | 中性的 | CAA、CAG、GAA、GAC |
| 甘氨酸 | 甘氨酸 | G | 中性的 | GGU、GGC、GGA、GGG |
| 组氨酸 | 他的 | H | 10%+, 90%- | 中国农业大学、中国农业大学 |
| 异亮氨酸 | 和 | 我 | 中性的 | 哦,哦,哦 |
| 亮氨酸 | 亮氨酸 | L | 中性的 | UUA、UUG、CUU、CUC、CUA、CUG |
| 赖氨酸 | 赖氨酸 | K | (+) | AAA、AAG |
| 蛋氨酸 | 蛋氨酸 | 中号 | 中性的 | 八月 |
| 苯丙氨酸 | 苯丙氨酸 | F | 中性的 | UUU、UUC |
| 脯氨酸 | 专业版 | 磷 | 中性的 | CCU、CCC、CCA、CCG |
| 安详 | 成为 | S | 中性的 | UCU、UCC、UCA、UCG、AGU、AGC |
| 苏氨酸 | 苏尔 | 时间 | 中性的 | ACU、ACC、ACA、ACG |
| 色氨酸 | 色氨酸 | 瓦 | 中性的 | UGG |
| 酪氨酸 | 提尔 | 是 | 中性的 | UAU、UAC |
| 缬氨酸 | 瓦尔 | V | 中性的 | GUU, GUC, GUA, GUG |
| 开始 | 八月 | |||
| 停止 | UAA、UAG、UGA |
如果在 mRNA 链上我们有(之前的例子):
| 一个 | U | G | C | G | G | C | 一个 | C | G | 一个 | U | U | U | C | C | U | G | 一个 | 一个 | C | C | C | G | U | G | 一个 |
用氨基酸的语言来说,这可以翻译为(氨基酸的 3 个字符代码的组合):
| 开始 | 精氨酸 | 他的 | 天冬氨酸 | 苯丙氨酸 | 亮氨酸 | 阿森 | 专业版 | 停止 |
| 开始 | 右 | H | D | F | L | 氮 | 磷 | 停止 |
那是:
开始 – 精氨酸 – 组氨酸 – 天冬氨酸 – 苯丙氨酸 – 亮氨酸 – 天冬酰胺 – 脯氨酸 – STOP
或作为极性:
| 开始 | (+) | 10%(+)90%(-) | (-) | 中性的 | 中性的 | 中性的 | 中性的 | 停止 |
表 1 中的信息以图形方式总结在 图6 来自以下:
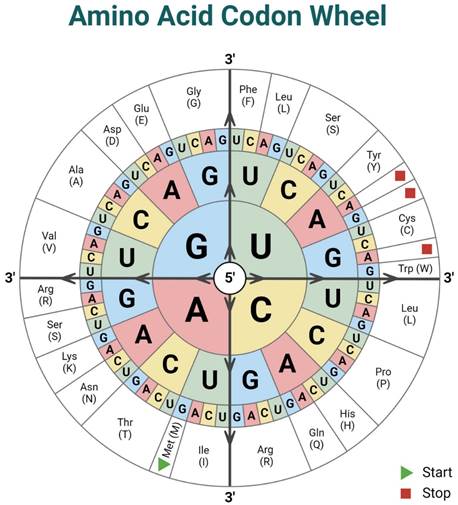
图6 – 密码子轮
为什么我们如此坚持 DNA、RNA、mRNA、氨基酸或氨基酸序列(更广泛地称为蛋白质)?因为,这些氨基酸序列具有功能,该功能是由它们在空间上折叠或排列的方式赋予的。这种 3D 排列是根据该蛋白质中每个氨基酸的极性来完成的。由于细胞质中的环境是水性的(因此是极性的),因此 3D 结构的出现遵循几个标准:
- 非极性氨基酸需要尽可能深地隐藏在结构内部,因为它不喜欢水;
- 极性氨基酸会尽可能靠近极性相反的氨基酸;
- 极性氨基酸会尽可能远离具有相似极性的氨基酸。
这种空间构象决定了活性位点的外观,活性位点允许与另一种蛋白质、酶(使过程运行得更快且能耗更少)、药物中的活性物质分子偶联。因为药物(大多数时候)的工作原理是一把假钥匙,适合打开蛋白质的特定锁/活性位点。
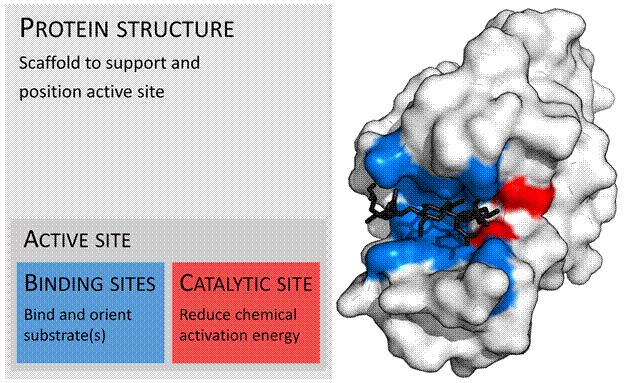
图7 – 由于 3D 排列而出现的蛋白质活性位点
对于那些想要深入研究这个主题的人,我在最后留下了“蛋糕上的糖果”,一些解释视频。
六.不是结论而是假设!
有一次,我曾说过: DNA 编码精子受精卵子生长和发育所需的信息,直至获得功能齐全的有机体! 这是确定无疑的事情,可以看出 图8。
从 Manuela Murariu 和 Gabi Drochioiu 于 2012 年发表在《Biosystems》杂志(IF 2.0)上的一篇文章中,我了解了生物体的生物结构理论。他们谈论生物学中的超分子概念,以及尤金·马科夫斯基如何尝试并部分成功地解释生物系统中“死”和“活”之间的差异。
我想提出的假设是:
与蛋白质合成无关的信息(在人类中——几乎97%的DNA信息在蛋白质合成中没有作用,但也编码胚胎生长发育到功能齐全的有机体阶段的信息, 图8) 这些生物上层结构是否也编码了生命与非生命之间的差异?这些编码生物场吗?
来这里见你!
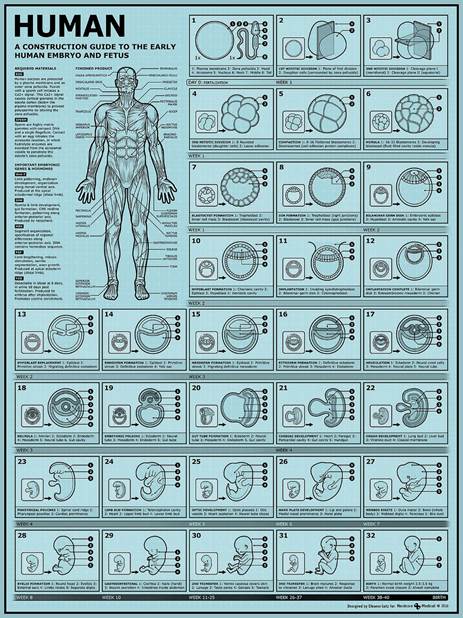
图8 – 人类胚胎从受孕到出生的发育过程
七.选择性参考书目
为了便于引用,同时也为了在在线环境中跟踪信息,我们选择在文本中以二维码的形式引用提供附加信息的网页。
Dawkins, R. – Gena Egoistă,布加勒斯特,技术编辑,2001 年(译:Dan Crăciun)
Darymple, G.B.,《地球时代》,斯坦福大学,斯坦福大学出版社,1991 年;
Manhesa, G.、Allègre, C.J.、Dupréa, B.、Hamelin, B. – 基性-超基性层状复合体的铅同位素研究:关于地球年龄和原始地幔特征的推测 – 地球与行星科学快报,1980 年;
Dinu, V.、Trutia, E.、Popa-Cristea, E.、Popescu, A. – 医学生物化学,小论文,布加勒斯特,医学版,1996 年
Murariu, M., Drochioiu, G. – 生命系统的生物结构理论 – 生物系统, 109-2, 126-132, 2012
作者

- 选择语言
 Română/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Română/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Deutsch/de/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Deutsch/de/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ English/en/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
English/en/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Español/es/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Español/es/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Esperanto/eo/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Esperanto/eo/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Français/fr/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Français/fr/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Italiano/it/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Italiano/it/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Latīna/la/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Latīna/la/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ Português/pt/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
Português/pt/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ 中文(简体)/zh/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
中文(简体)/zh/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ 日本語/ja/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
日本語/ja/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/ 한국어/ko/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
한국어/ko/carti/infinit/infinitezimalul-biologic-baze-de-date-organice/
编辑翻译